Imaginez un chantier où le peintre commence à peindre les murs alors que les maçons n'ont pas encore fini de monter la brique. C'est exactement ce qui arrive dans vos pipelines GitHub Actions quand la logique de dépendance est floue.
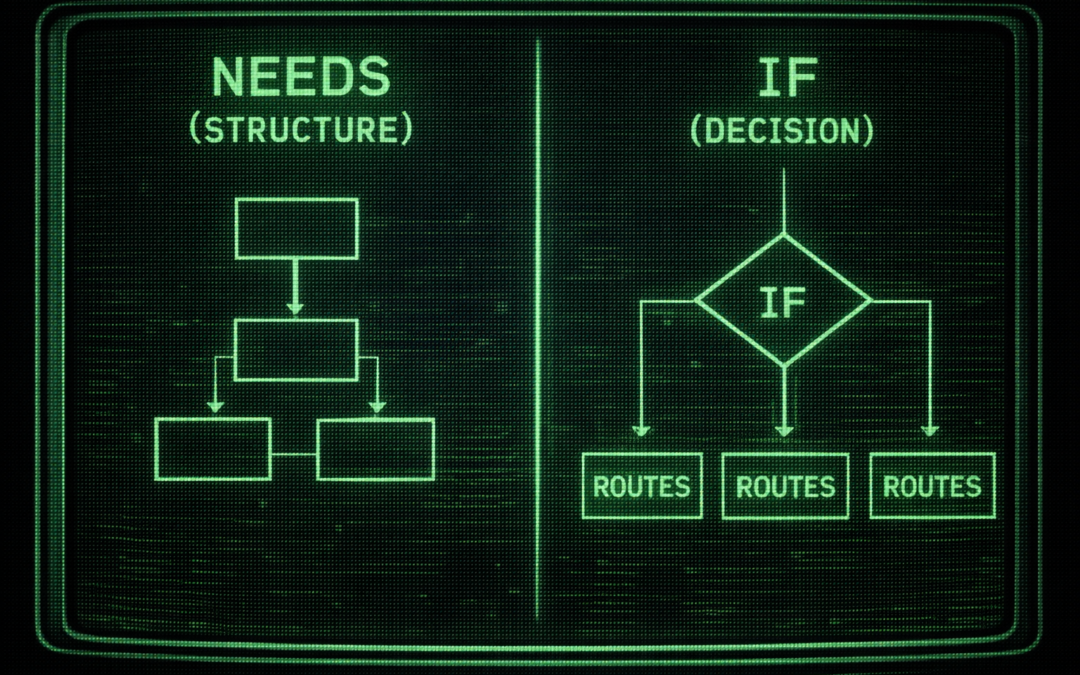
Le problème est classique : on veut qu'un job ne s'exécute pas tant qu'un autre n'est pas terminé. Intuitivement, on cherche une condition. On hésite entre forcer un ordre (needs) ou vérifier une validation (if).
Pourtant, ces deux attributs ne jouent pas dans la même cour. L'un construit le squelette de votre CI/CD, l'autre en est le garde-fou. Si vous les confondez, vous créez des pipelines "magiques" ou instables où les données ne circulent pas et où les échecs ne sont pas correctement interceptés.
1. Le Modèle Mental : Structure vs Logique
Avant de toucher au YAML, retenez cette distinction fondamentale :
Chaînage : Pour accéder aux outputs du job précédent (impossible sans needs !).
Sécurité : Si le job build échoue, le job test est automatiquement annulé (skippé).
3. if : Le Garde-Fou
if intervient au moment de l'exécution. Le job est planifié, mais avant de démarrer, l'exécuteur vérifie la condition.
jobs:
deploy:
runs-on: ubuntu-latest
# Condition basée sur le contexte, pas sur un autre job
if: github.ref == 'refs/heads/main'
steps:
- run: echo "Déploiement en Prod"
Exemple de contexte métier :
Utilisez if: failure() pour envoyer une notification Slack uniquement si le pipeline plante.
4. Comparatif Stratégique
Critère
needs
if
Niveau
Structure du pipeline
Logique d'exécution
Ordonnancement
Oui (Graphe)
Non
Accès aux outputs
Oui
Non
Usage principal
Étapes logiques
Règles métier / Branches
5. La Règle d'Or du Pipeline Mature
⚡ LE MANTRA À GRAVER DANS LE MARBRE :
👉 Si un job dépend d’un autre (ordre) → utilisez needs
👉 Si un job dépend d’un contexte (branche, tag, event) → utilisez if
Dans un environnement industriel, on ne choisit pas l'un contre l'autre. On les combine :
deploy-prod:
needs: [test, security-scan] # ORDRE : J'attends que les tests soient verts
if: github.ref == 'refs/heads/main' # CONTEXTE : Je ne déploie que si je suis sur Main
runs-on: ubuntu-latest
steps:
- run: ./deploy.sh
C'est le modèle recommandé : needs garantit l'intégrité structurelle (le "quand"), et if garantit la conformité logique (le "pourquoi").
6. Regard de Coach : Le pipeline est un produit
Au-delà de la syntaxe YAML, comprendre cette différence relève de la culture Craftsmanship.
🛡️ Lisibilité : Un pipeline avec des needs bien placés est auto-documenté.
🛡️ Intention : Ne cachez pas une dépendance derrière un if complexe. Rendez-la explicite.
🛡️ Robustesse : Un pipeline "plat" (sans needs) est un risque de sécurité : vos jobs pourraient s'exécuter en parallèle et déployer un code non testé.
Par Nicolas DELAHAYE | v.1974 | Architecte Solution
STATUS: NETWORK_ARCHITECTURE_UPGRADE
1. Le Constat : Pourquoi tuer l'Ingress ?
Pendant des années, l'objet Ingress a été le standard de facto. Couplé à des contrôleurs comme NGINX, Traefik ou HAProxy, il a fait le travail. Mais soyons honnêtes, à l'échelle, c'est devenu un cauchemar de maintenance.
Les limites sont structurelles :
L'enfer des Annotations : Pour faire du rate-limiting ou du rewrite, vous injectez des annotations spécifiques au contrôleur (vendor lock-in).
Tout ou rien : L'objet Ingress mélange la configuration de l'infrastructure (TLS, IP) et le routage applicatif (Paths). Difficile de séparer les rôles Ops et Dev.
HTTP Only : Pas de support natif propre pour TCP, UDP ou gRPC sans "hacks".
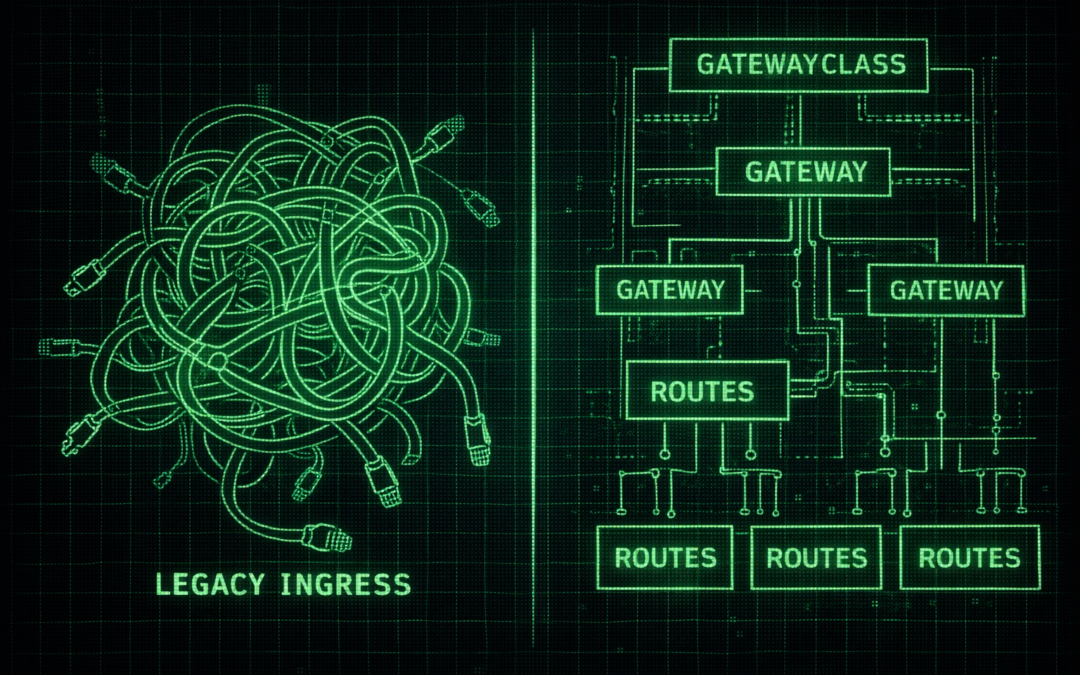
2. Gateway API : Une Révolution Architecturale
La Gateway API n'est pas une v2 de l'Ingress. C'est une refonte complète basée sur une architecture orientée Rôles. Elle introduit plusieurs ressources (CRDs) pour découpler les responsabilités.
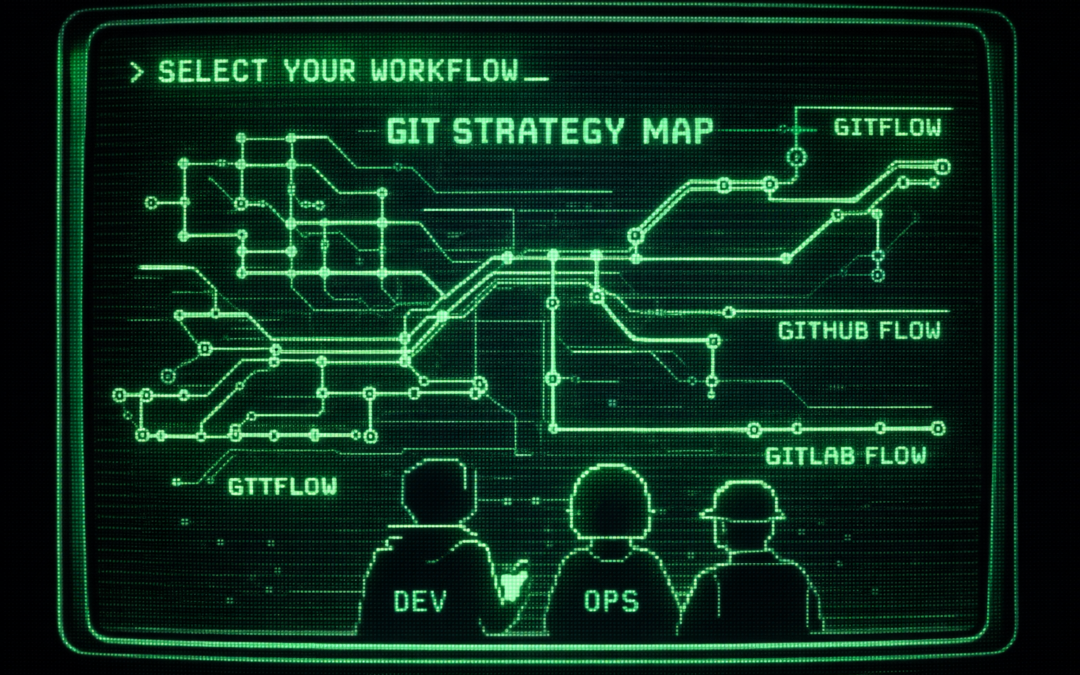
Choisir son Flow : Le miroir de votre organisation
Par Nicolas DELAHAYE | Article Pilier | Stratégie & DevOps
STATUS: ARCHITECTURAL_ANALYSIS_IN_PROGRESS
L'Erreur Originelle : Le Flow comme simple outil
Dans l'univers du développement logiciel, une conversation revient inlassablement lors du lancement d'un projet : "Quel workflow Git allons-nous utiliser ?". Trop souvent, la réponse est technique : "On va faire du GitFlow parce que c'est robuste" ou "GitHub Flow, c'est ce que font les start-ups, c'est plus moderne".
C'est une erreur fondamentale de jugement. Choisir son flux de gestion de branches n'est pas une décision technique comparable au choix d'une base de données ou d'un framework JavaScript. Votre Git Flow est le reflet direct de votre gestion de produit, de la confiance interne de votre équipe et de votre tolérance au risque.
Si votre workflow Git frotte, c'est souvent parce qu'il est en désaccord avec votre réalité organisationnelle. Un workflow complexe comme GitFlow peut paralyser une équipe agile cherchant le déploiement continu, tandis qu'un flux trop simple comme GitHub Flow peut mettre en danger une équipe soumise à des régulations strictes.
1. L'impact du Cycle de Développement et du Cadre (Frameworks)
La première contrainte qui doit guider votre choix est le rythme cardiaque de votre projet. Comment planifiez-vous la valeur que vous livrez ?
Le Mode Cascade / Cycle en V (Prince 2, PMI)
Dans des environnements régulés ou des projets au forfait classique, le cycle de développement est souvent prédictif. On spécifie, on développe, on teste, on livre. Les versions majeures sortent tous les 3 ou 6 mois.
Ici, le flow doit supporter la notion de "Release" figée. Vous avez besoin de stabiliser une version tout en continuant à développer la suivante. GitFlow est structurellement adapté à ce besoin. Il permet de maintenir plusieurs versions en parallèle et de gérer rigoureusement les correctifs.
Le Mode Agile Itératif (Scrum)
En Scrum, le rythme est dicté par le Sprint (souvent 2 semaines). À la fin du Sprint, vous devez avoir un incrément potentiellement livrable.
Le flow doit ici supporter une branche d'intégration (souvent Develop) qui accumule les fonctionnalités validées pendant le sprint. Cependant, la lourdeur de GitFlow peut commencer à peser si l'équipe souhaite livrer pendant le sprint.
Le Mode Flux Tendu (Kanban / Lean)
En Kanban, il n'y a plus de notion de "lot" ou de "version" au sens classique. Une fonctionnalité est prête ? Elle part en production.
Dans ce contexte, toute branche de "longue durée" (comme une branche Develop qui ne serait mergée que tous les mois) devient un stock, donc un déchet. Ici, un flow comme GitHub Flow, basé sur une branche principale unique et des déploiements fréquents, est impératif[.
2. Les Normes de l'Équipe : Solo, Pair ou Mercenaire ?
La sociologie de votre équipe influence la manière dont le code doit transiter. Le workflow est aussi un outil de contrôle qualité et de communication.
Le cas du "Mercenaire" ou de l'équipe distribuée
Si vous travaillez avec des freelances, des contributeurs Open Source ou des équipes hétérogènes avec un turnover élevé, la confiance "par défaut" n'est pas toujours possible. Votre flow doit agir comme un sas de sécurité.
La branche Main (ou Master) devient un sanctuaire. Personne ne push dessus. Le workflow doit imposer des Feature Branches strictes et le passage obligatoire par des Merge Requests (MR) ou Pull Requests. C'est le "Gatekeeper" (Tech Lead) qui valide l'entrée.
Le cas du "Pair Programming" et du "Mob Programming"
À l'inverse, si votre équipe pratique le Pair Programming intensif, la revue de code est effectuée en temps réel, pendant l'écriture.
Imposer une Pull Request formelle et attendre 4h qu'un collègue la valide est un gaspillage pur. Ces équipes s'orientent souvent vers du Trunk-Based Development ou un GitHub Flow très accéléré, car la qualité est injectée à la source, pas au contrôle final.
3. Le conflit de pouvoir : Qui tient le manche du déploiement ? (Dev vs Ops)
C'est souvent l'angle mort des choix de workflow. Qui a la responsabilité de la mise en production ? Cette question définit la direction du flux : Push ou Pull ?
Scénario A : Le modèle "Push" (Pression sur l'Ops)
L'équipe de développement considère que son travail est fini quand la fonctionnalité est mergée sur Main. Elle "pousse" le code.
Impact sur le Flow : Cela implique souvent l'utilisation de GitHub Flow ou de CI/CD automatisé[. L'Ops (ou la plateforme) subit le rythme des développeurs. Si le pipeline est vert, ça part en prod. C'est le modèle des équipes "You build it, you run it".
Scénario B : Le modèle "Pull" (Responsabilité Ops)
Ici, l'équipe Ops (ou SRE) est garante de la stabilité. Elle refuse que chaque merge parte en prod automatiquement.
Impact sur le Flow : L'équipe Dev livre un package (un Tag) ou met à jour une branche de Release. L'Ops décide quand il "tire" (pull) ce tag pour le déployer.
C'est là que GitLab Flow brille particulièrement. Il permet de réconcilier ces deux mondes en introduisant des branches d'environnement (ex: production, pre-production). Les devs mergent sur Main, mais le déploiement effectif ne se fait que lorsque l'on merge (ou cherry-pick) vers la branche de production.
4. Anatomie des options : De la théorie à la pratique Git
Maintenant que le contexte humain est posé, regardons comment cela se traduit techniquement. Comme vous l'avez mentionné, la gestion des branches est la clé de voûte du système.
Les Branches Canoniques
Peu importe le flow, vous manipulerez ces concepts :
Master/Main Branch : Représente l'état "prêt pour la production" du code. C'est la vérité terrain.
Develop Branch : Le point d'intégration pour les nouvelles fonctionnalités. C'est le "brouillon propre" de la prochaine version.
Feature Branches : Créées depuis develop (ou main selon le flow) pour implémenter une nouveauté. Elles isolent le travail en cours.
Release Branches : Branchées depuis develop pour préparer une livraison (gel du code, tests finaux, documentation).
Hotfix Branches : Créées depuis master pour corriger une urgence en prod. C'est le "pompier" du système.
Option 1 : GitFlow (Le "Structured Approach")
Conçu par Vincent Driessen, c'est le modèle le plus strict. Il utilise toutes les branches citées ci-dessus.
Fonctionnement : On développe sur feature, on merge sur develop. Quand on est prêt, on crée une release. Une fois validée, elle est mergée sur main ET sur develop.
Pour qui ? Les grandes équipes, les projets complexes, ceux qui ont des cycles de release planifiés.
Le piège : La complexité de gestion des merges et la lourdeur pour un simple fix.
Option 2 : GitHub Flow (Le "Agile Approach")
Une approche simplifiée, populaire pour le déploiement continu.
Fonctionnement : Il n'y a que main et des feature branches . Une feature terminée = une Pull Request = un Merge sur Main = un Déploiement .
Pour qui ? Les petites/moyennes équipes, les start-ups, ceux qui veulent itérer très vite.
Le piège : La branche main peut devenir instable si les tests (CI) ne sont pas bétons, car tout merge est potentiellement en prod.
Option 3 : GitLab Flow (Le "Middle Ground")
Une alternative qui tente de résoudre les manques de GitFlow (trop complexe) et de GitHub Flow (trop simpliste pour la prod complexe) .
Fonctionnement : Le développement se fait sur main (comme GitHub Flow), mais on ajoute des branches "d'environnement" ou de "release" en aval (ex: pre-production, production). On merge de l'une vers l'autre pour promouvoir le code.
Pour qui ? Les équipes qui font du CI/CD mais qui ont besoin de valider manuellement des environnements (UAT, Staging) avant la prod.
5. Checklist de Décision : Trouvez votre Flow
Avant de lancer git init, réunissez votre Tech Lead, votre Product Owner et votre Ops, et répondez à ces questions :
📋 La Matrice de Choix
□ Avez-vous besoin de maintenir plusieurs versions en production (v1.0, v2.0) ? Oui → GitFlow (ou GitLab Flow avec branches release ). Non → GitHub Flow.
□ Quelle est la fréquence de vos déploiements ? Plusieurs fois par jour → GitHub Flow. Une fois toutes les 2 semaines/mois → GitFlow.
□ Votre équipe est-elle Junior ou Senior ? Junior → GitFlow peut structurer et rassurer. Senior/Autonome → GitHub Flow libère la vélocité.
□ Avez-vous des environnements de validation stricts (QA, UAT) avant la Prod ? Oui → GitLab Flow est idéal pour mapper les branches aux environnements.
□ Qui déploie ? C'est automatisé au merge → GitHub Flow. C'est l'Ops qui décide → GitLab Flow ou GitFlow.
📚 Sources & Documentation Officielle
// Liste des pointeurs mémoire utilisés pour cette analyse :
Par Nicolas DELAHAYE | v.1974 | Architecte Solution
STATUS: NETWORK_RECOVERY_MODE
Monter un Lab Kubernetes VirtualBox avec Fedora Server est un excellent choix technique, mais c'est aussi un redoutable test pour vos compétences réseau. Le symptôme est classique : vos VMs ne sortent pas sur Internet et votre Mac refuse de s'y connecter en SSH.
Le problème ne vient pas de Fedora, mais d'une confusion courante sur le rôle du NAT Network. Contrairement à une idée reçue, la VM ne doit pas "router" via votre host pour sortir. Elle doit utiliser l'abstraction fournie par VirtualBox.
1. Le Diagnostic : Pourquoi votre NAT Network échoue
En configurant vos IP manuellement sans activer de serveur DHCP sur le NAT Network, vous avez créé des nœuds isolés. Sans DHCP, Fedora ne reçoit pas de Default Gateway (passerelle par défaut). Sans passerelle, la VM ne sait pas par où envoyer ses paquets pour atteindre 8.8.8.8.
De plus, le NAT Network est un réseau privé. Par défaut, il n'autorise pas votre MacBook à "entrer" pour initier une session SSH sans une règle de Port Forwarding complexe.
[Image of the OSI model networking layers]
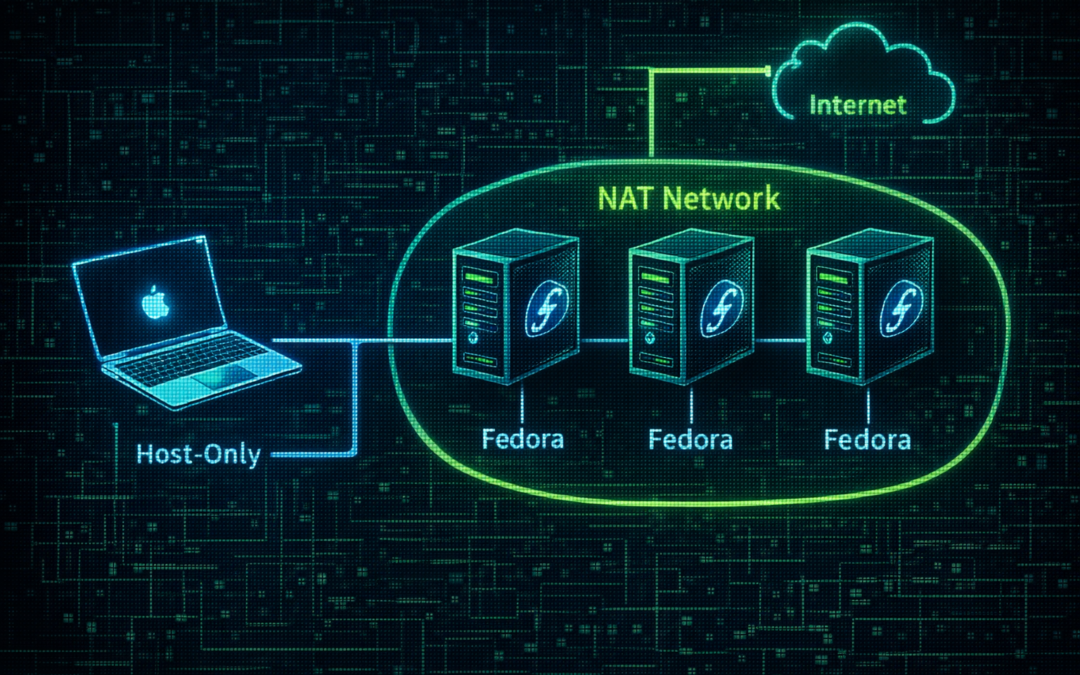
2. La Solution : L'Architecture à Double Interface
Pour un lab Kubernetes stable et conforme aux bonnes pratiques DevSecOps, nous allons utiliser deux cartes réseau par VM. Cette séparation des flux est la clé :
NIC 1 (NAT Network) : Dédié à la sortie vers Internet (mises à jour dnf, téléchargement d'images Docker).
NIC 2 (Host-Only) : Dédié à l'administration SSH depuis votre Mac et aux communications internes du cluster.
Schéma de flux : VM (enp0s3) ----> VirtualBox NAT Engine ----> Internet Mac (vboxnet0) <----> VM (enp0s8) [SSH & Kube API]
DHCP :DOIT être activé (C'est lui qui donnera la route par défaut).
B. Paramétrer le Host-Only
Vérifiez que vous avez une interface vboxnet0 (souvent en 192.168.56.1) créée dans le gestionnaire de réseau hôte.
4. Configuration Fedora via nmcli
Fedora Server utilise NetworkManager. Oubliez la modification manuelle des fichiers ifcfg, utilisez nmcli pour une configuration persistante et propre.
# 1. Configurer l'interface Internet (NAT Network)nmcli con add type ethernet ifname enp0s3 con-name internet ipv4.method auto
nmcli con up internet
# 2. Configurer l'interface SSH/Admin (Host-only)nmcli con add type ethernet ifname enp0s8 con-name admin \
ipv4.method manual \
ipv4.addresses 192.168.56.11/24
nmcli con up admin
Crucial : En laissant la première interface en auto (DHCP), Fedora va automatiquement définir la passerelle 10.0.2.1 comme route par défaut. Votre VM peut maintenant sortir !
5. Automatisation avec Vagrant
Pour éviter de refaire cette configuration manuellement sur vos trois nœuds (Control-Plane, Worker1, Worker2), voici le Vagrantfile optimisé pour votre Lab Kubernetes VirtualBox.
Vagrant.configure("2") do |config|
config.vm.box = "fedora/40-cloud-base"
nodes = {
"cp-master" => "192.168.56.11",
"worker-1" => "192.168.56.21",
"worker-2" => "192.168.56.22"
}
nodes.each do |name, ip|
config.vm.define name do |node|
node.vm.hostname = name
# Interface 1 : NAT Network (Auto DHCP via Vagrant)
node.vm.network "private_network", type: "dhcp", virtualbox__intnet: "nat-k8s"
# Interface 2 : Host-only (IP Statique pour SSH)
node.vm.network "private_network", ip: ip
node.vm.provider "virtualbox" do |vb|
vb.memory = 2048
vb.cpus = 2
end
end
end
end
6. Conclusion : Une base saine pour Kubeadm
Une fois cette architecture réseau en place, vous verrez que l'installation de Kubernetes avec kubeadm devient fluide. Pourquoi ? Parce que les composants comme Etcd ou l'API Server pourront s'écouter sur l'interface Host-Only stable, tandis que les pods pourront sortir chercher leurs images via le NAT Network.
Rappelez-vous : dans un environnement virtualisé, la simplicité est une vertu. En séparant l'administration (Host-Only) de la sortie (NAT), vous imitez les architectures Cloud réelles.
Comparatif Distributions Linux : Comprendre la Jungle des Paquets
Par Nicolas DELAHAYE | v.1974 | Architecte Solution
STATUS: OS_FAMILY_ANALYSIS
Il existe des centaines de distributions Linux, mais en réalité, elles ne forment que quelques grandes familles. Si vous avez l'impression de toujours tomber soit sur yum, soit sur apt-get, votre intuition est bonne.
Réaliser un comparatif des distributions Linux pertinent ne consiste pas à regarder l'interface graphique (puisque nous travaillons en Headless), mais à analyser leur ADN : leur gestionnaire de paquets, leur philosophie de sécurité et leur cycle de vie.
1. Les Grandes Familles et leurs Gestionnaires
La Famille Debian (Le Standard)
Distros : Debian, Ubuntu, Linux Mint.
Gestionnaire :apt / apt-get (.deb).
Pourquoi elle domine : Équilibre parfait entre stabilité (Debian Stable) et facilité d'usage (Ubuntu).
La Famille Red Hat & Fedora (L'Innovation & l'Entreprise)
C'est ici que se joue le futur du Linux d'entreprise. On distingue deux branches majeures :
Fedora Project : C'est la distribution "amont" (upstream). Orientée communauté et innovation, elle intègre les dernières versions de kernels et d'outils. Si une techno est dans Fedora aujourd'hui, elle sera dans la prod mondiale dans 2 ans.
RHEL / Rocky / Alma : La branche stable "aval" (downstream), dérivée des versions stabilisées de Fedora.
Gestionnaire :dnf (le successeur moderne de yum).
La Famille Alpine (Le Minimaliste)
Gestionnaire :apk.
Usage : Conteneurs Docker ultra-légers (5 Mo).
2. Comparatif des Distributions Linux par Critères
Distro
Communauté
Sécurité (Défaut)
Taille / Poids
Usage Type
Debian
⭐⭐⭐⭐⭐
⭐⭐⭐⭐
Moyenne
Serveur / VM stable
Fedora
⭐⭐⭐⭐
⭐⭐⭐⭐
Moyenne
Poste Dev / Innovation
Rocky / Alma
⭐⭐⭐
⭐⭐⭐⭐⭐
Moyenne
Production Critique
Alpine
⭐⭐⭐
⭐⭐⭐⭐⭐
Très Petite
Containers Docker
3. Zoom sur Fedora : Pourquoi s'y intéresser ?
Utiliser Fedora (via le Projet Fedora) est un choix stratégique pour un architecte. Contrairement à Debian qui privilégie des paquets parfois anciens mais éprouvés, Fedora propose des versions très récentes de Docker, Podman ou Python.
C'est la distribution idéale pour monter une VM de développement "Cutting Edge" tout en restant compatible avec les commandes dnf que vous retrouverez en production sur RHEL.
Pour offrir les meilleures expériences, nous utilisons des technologies telles que les cookies pour stocker et/ou accéder aux informations des appareils. Le fait de consentir à ces technologies nous permettra de traiter des données telles que le comportement de navigation ou les ID uniques sur ce site. Le fait de ne pas consentir ou de retirer son consentement peut avoir un effet négatif sur certaines caractéristiques et fonctions.
Fonctionnel
Toujours activé
L’accès ou le stockage technique est strictement nécessaire dans la finalité d’intérêt légitime de permettre l’utilisation d’un service spécifique explicitement demandé par l’abonné ou l’utilisateur, ou dans le seul but d’effectuer la transmission d’une communication sur un réseau de communications électroniques.
Préférences
L’accès ou le stockage technique est nécessaire dans la finalité d’intérêt légitime de stocker des préférences qui ne sont pas demandées par l’abonné ou l’internaute.
Statistiques
Le stockage ou l’accès technique qui est utilisé exclusivement à des fins statistiques.Le stockage ou l’accès technique qui est utilisé exclusivement dans des finalités statistiques anonymes. En l’absence d’une assignation à comparaître, d’une conformité volontaire de la part de votre fournisseur d’accès à internet ou d’enregistrements supplémentaires provenant d’une tierce partie, les informations stockées ou extraites à cette seule fin ne peuvent généralement pas être utilisées pour vous identifier.
Marketing
L’accès ou le stockage technique est nécessaire pour créer des profils d’internautes afin d’envoyer des publicités, ou pour suivre l’utilisateur sur un site web ou sur plusieurs sites web ayant des finalités marketing similaires.